

























-620.svg)

循环智能的主动学习(Active Learning)技术探索与实践:减少 80% 标注量
-

2020-06-09
-

产品 · 技术 · 实践

但由于需要收集分析的数据量急剧增加,从大量数据中手动提取有用的知识变得非常困难和不可能,因此需要利用自然语言处理(NLP)和数据挖掘(Data Mining)技术来帮助企业挖掘和发现有用的知识。
为了让机器快速学习,对沟通数据(电话录音、在线IM沟通记录)进行标注是必不可少的一步。但是,数据标注需要昂贵的人工或各种成本,面对海量的非结构化数据,如何经济又准确地进行标注是一个的棘手问题。

主动学习模型的分类
基于流的主动学习,它将未标记的数据一次性全部呈现给一个预测模型,该模型将预测结果(实例的概率值),根据某些评价指标(比如margin)计算评估实例的价值,随后应用主动学习决定是否应该花费一些预算来收集此数据的类标签,以进行后续的训练;
基于池的主动学习,这个通常是离线、反复的过程。这里向主动学习系统提供了大量未标记的数据,在此过程的每个迭代周期,主动学习系统都会选择一个或者多个未标记数据进行标记并用于随后的模型训练,直到预算用尽或者满足某些停止条件为止。此时,如果预测性能足够,就可以将模型合并到最终系统中,该最终系统为模型提供未标记的数据并进行预测。
一是仅基于独立同分布(IID)数据的不确定性进行主动学习,其中选择标准仅取决于针对每个数据自身信息计算的不确定性值;
二是通过进一步考虑实例相关性来进行主动学习,基于数据相关性的不确定性度量标准,利用一些相似性度量来区分数据之间的差异。
不确定性认为最重要的未标记数据是最接近当前分类边界的数据;
代表性认为可以表示一组新实例(例如一个聚类)的未标记数据更为重要;
不一致性认为在多个不同基准分类器中具有最大预测差异的未标记数据更为重要。
解决主动学习中类不平衡问题的方法
Zhu和Hovy [1] 等人尝试在主动学习过程中加入几种采样技术,以控制少数类和多数类中被标记实例数量的平衡,他们提出了一个基于bootstrap的过采样BootOS策略,该策略会基于该样本的所有k个邻居生成一个bootstrap样本。在每次迭代中,选择不确定性最大的数据进行标记并加入到已标记的数据集中。对应用该过采样策略来产生更加平衡的数据集,该数据集用于模型的重新训练。在每次迭代中选择具有最高不确定性的数据进行标记的操作涉及对已标记的数据进行重采样和使用重采样的数据集训练新的分类器,因此,此方法的可扩展性可能是大型数据集所关注的问题。
Ertekin [2] 等人提出VIRTUAL,一种过采样和主动学习相结合的方法,它建立了一种对少数群体进行重采样的自适应技术学习者选择最有用的样本进行过采样,然后该算法沿着的k个邻居之一的方向构造一个伪样本。该算法是一个在线算法,且它在构造伪样本后无需在整个标记数据集上重新训练就可以逐步构建分类器。 Bloodgood和Shanker [3] 等人利用了代价敏感学习的思想,用于在主动学习过程中处理失衡的数据分布,他们提出一种引入类特定代价的方法,扩展了基于SVM的主动学习的优势,然后利用经过适当调整的代价敏感的SVM,根据基于不确定性的“margin”标准选择数据。 Tomanek和Hahn [4] 等人提出了两种基于不一致显著性度量的主动学习方法。 Hualong Yu [5] 等人提出了一种基于极限学习机的主动在线加权模型。
真实场景的主动学习策略 LabelXL
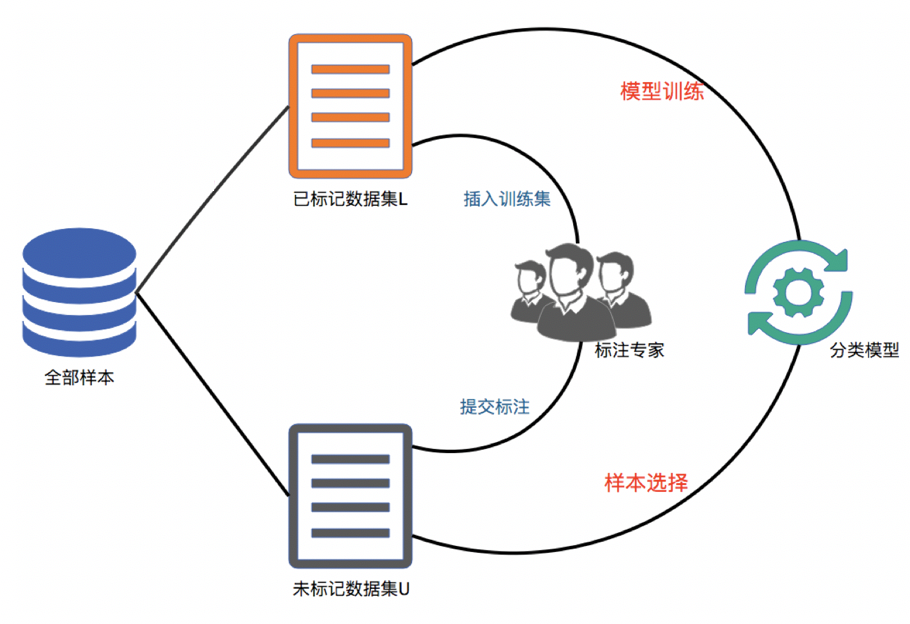
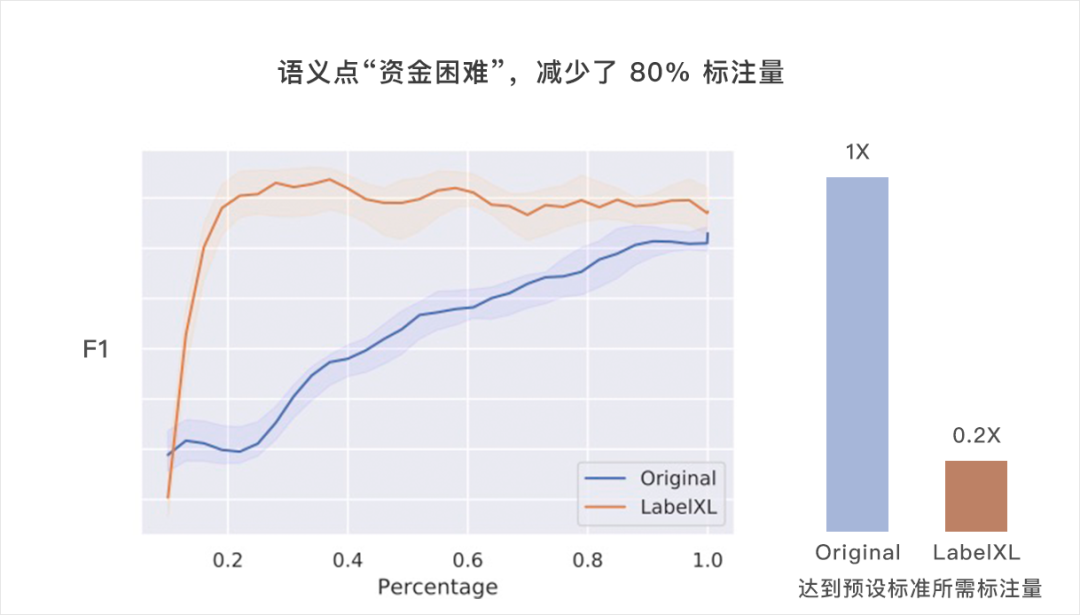
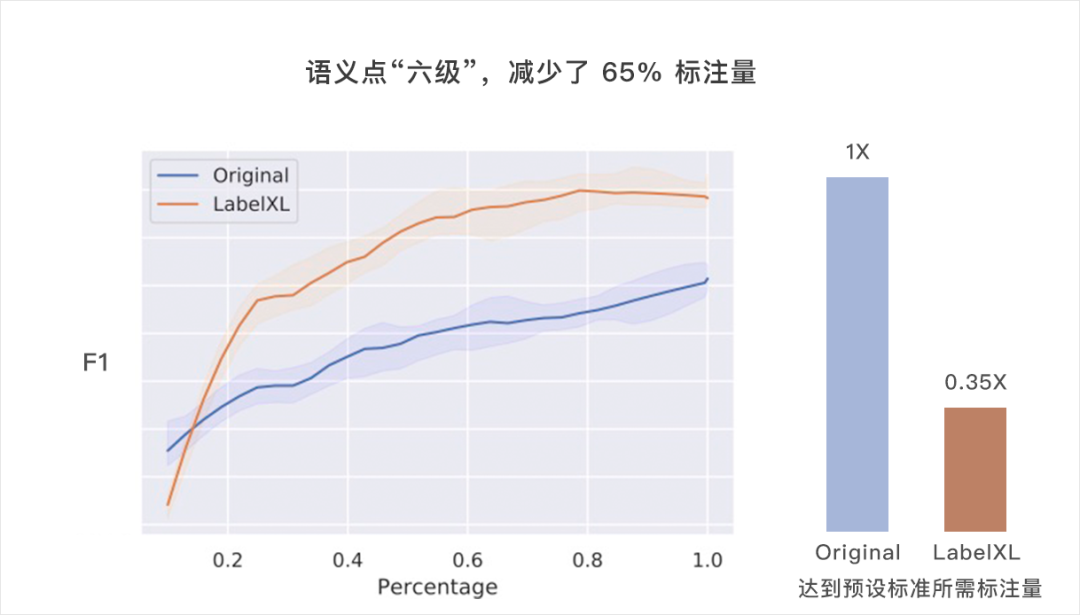
[1] J. Zhu and E. H. Hovy. Active learning for word sense disambiguation with methods for addressing the class imbalance problem. in Proc. EMNLP-CoNLL, 2007, pp. 783–790.
[2] S. Ertekin, J. Huang, and C. L. Giles. Adaptive Resampling with Active Learning. 2009.
[3] M. Bloodgood and K. Vijay-Shanker. Taking into account the differences between actively and passively acquired data: The case of active learning with support vector machines for imbalanced datasets. in Proc. Hum. Lang. Technol., 2009, pp. 137–140.
[4] K. Tomanek and U. Hahn. Reducing class imbalance during active learning for named entity annotation. in Proc. 5th Int. Conf. Knowl. Capture, 2009, pp. 105–112.
[5] H. Yu, X. Yang, S. Zheng, and C. Sun. Active Learning From Imbalanced Data: A Solution of Online Weighted Extreme Learning Machine. IEEE Trans. Neural Netw., vol. 30, no. 4, pp. 1088-1103, Apr. 2019.

产品演示或试用
循环智能
“让每一次沟通有更好的结果”
线索成单预测 | 销售执行力监督 | 智能质检 | 语音识别
> 详情请访问官网 rcrai.com

