

























-620.svg)



智能质检产品 Compliance
更贴合业务需求,更灵活配置的智能质检系统
-
灵活的流程质检
-
“多会话”关联质检
-
贴合业务的自定义字段
-
一键对接工单系统
-
可视化的系统界面
-
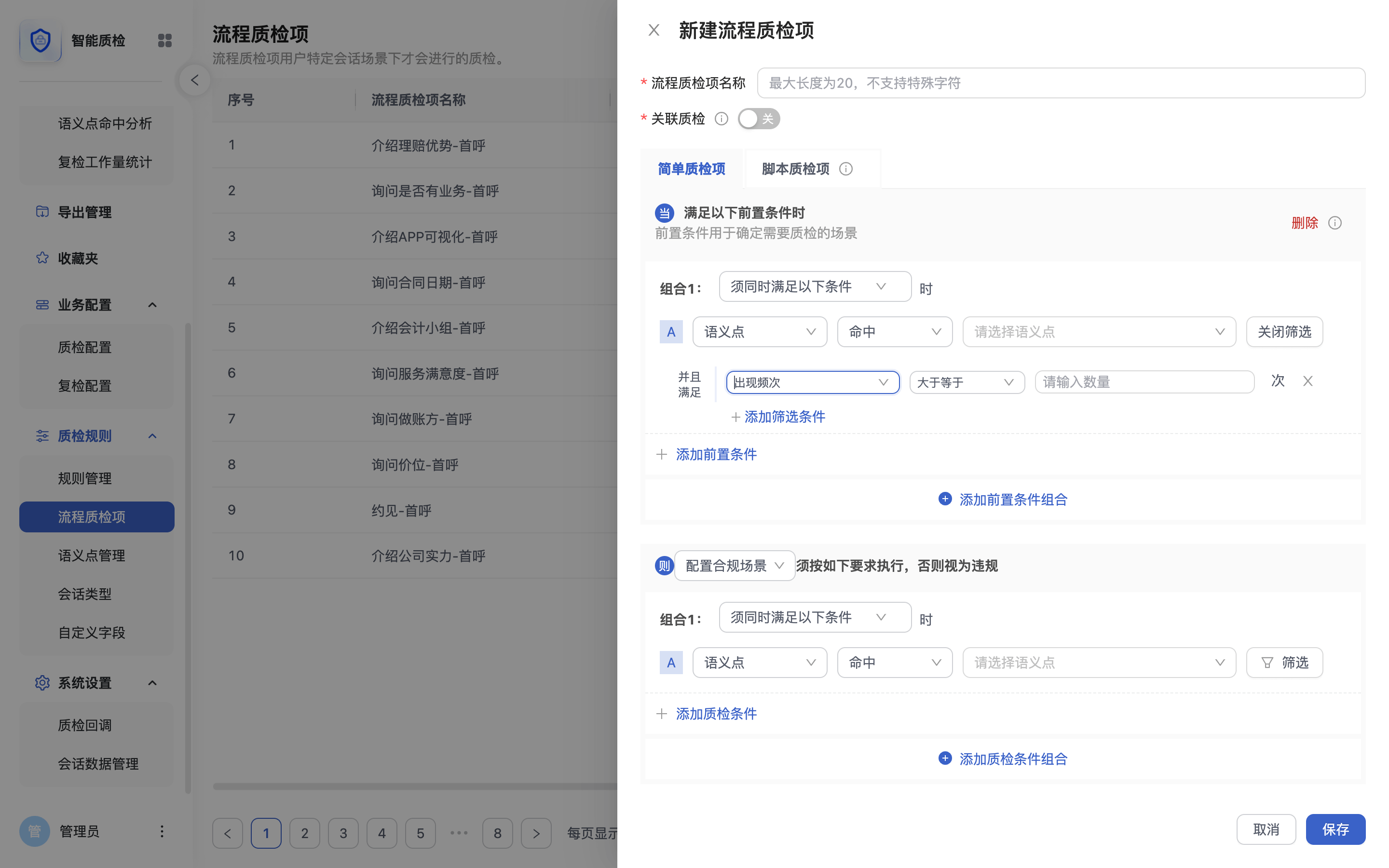
灵活的流程质检
流程质检是一种以业务人员更容易理解的方式,灵活配置各种复杂场景质检规则的创新方案。
可用于售前、售中、售后中一线人员的话术质检。
支持业务流程(SOP)执行情况质检。
也支持根据自身业务需要,按照特定场景配置不同的质检规则。
无需专门技术人员手工编写“与、或、非”等质检逻辑代码,业务人员更容易理解和使用。

-
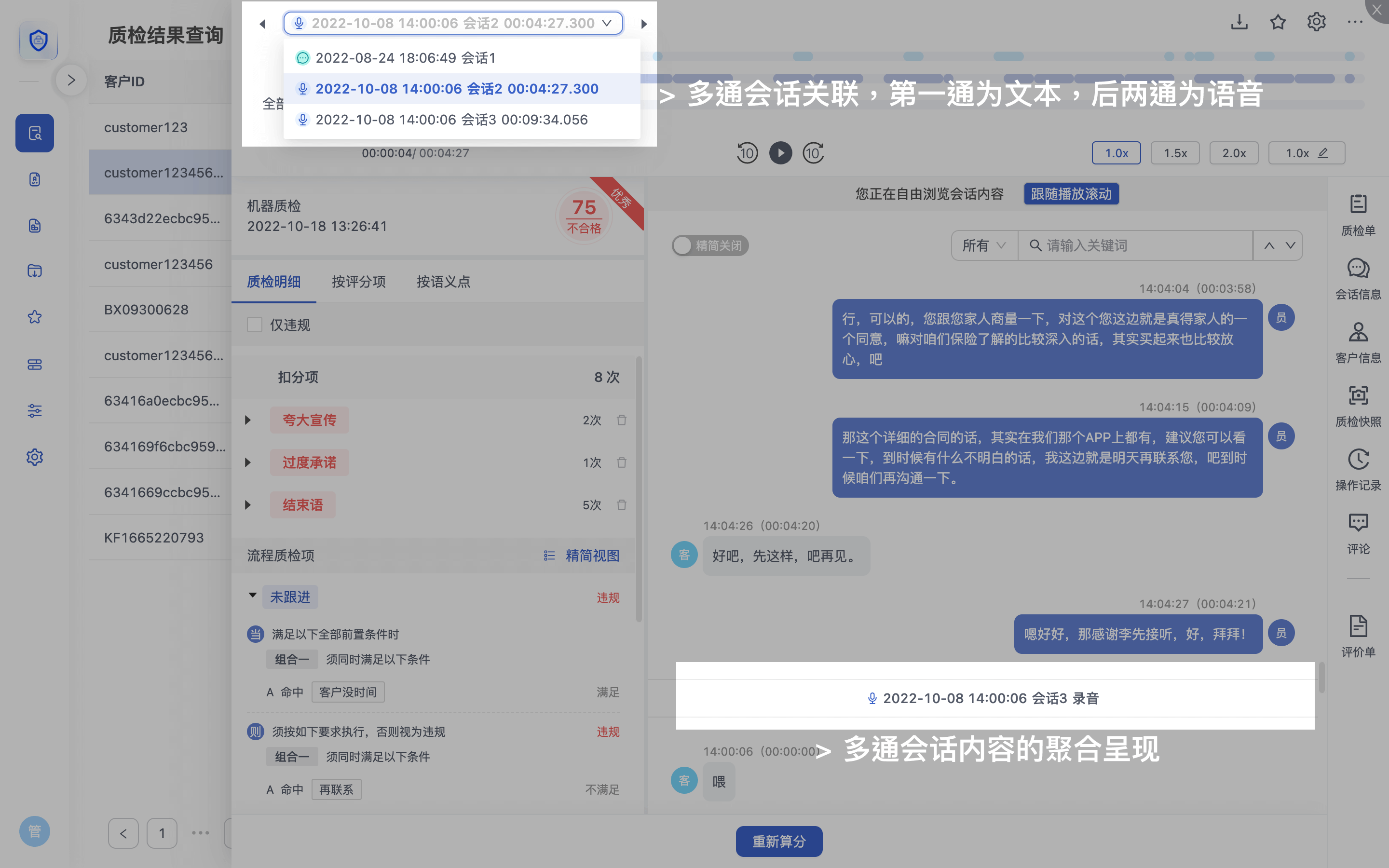
“多会话”关联质检
关联质检是指将多通会话(包含电话、APP、IM、企微等不同渠道的文本和语音数据)关联在一起,成组进行质检,输出一个质检结果。
关联维度可按照成功单的客户维度关联成组、会话ID关联成组、业务单据关联成组等多种方式。
可快速检查销售人员“跨渠道会话”的SOP执行情况和违规情况。
-
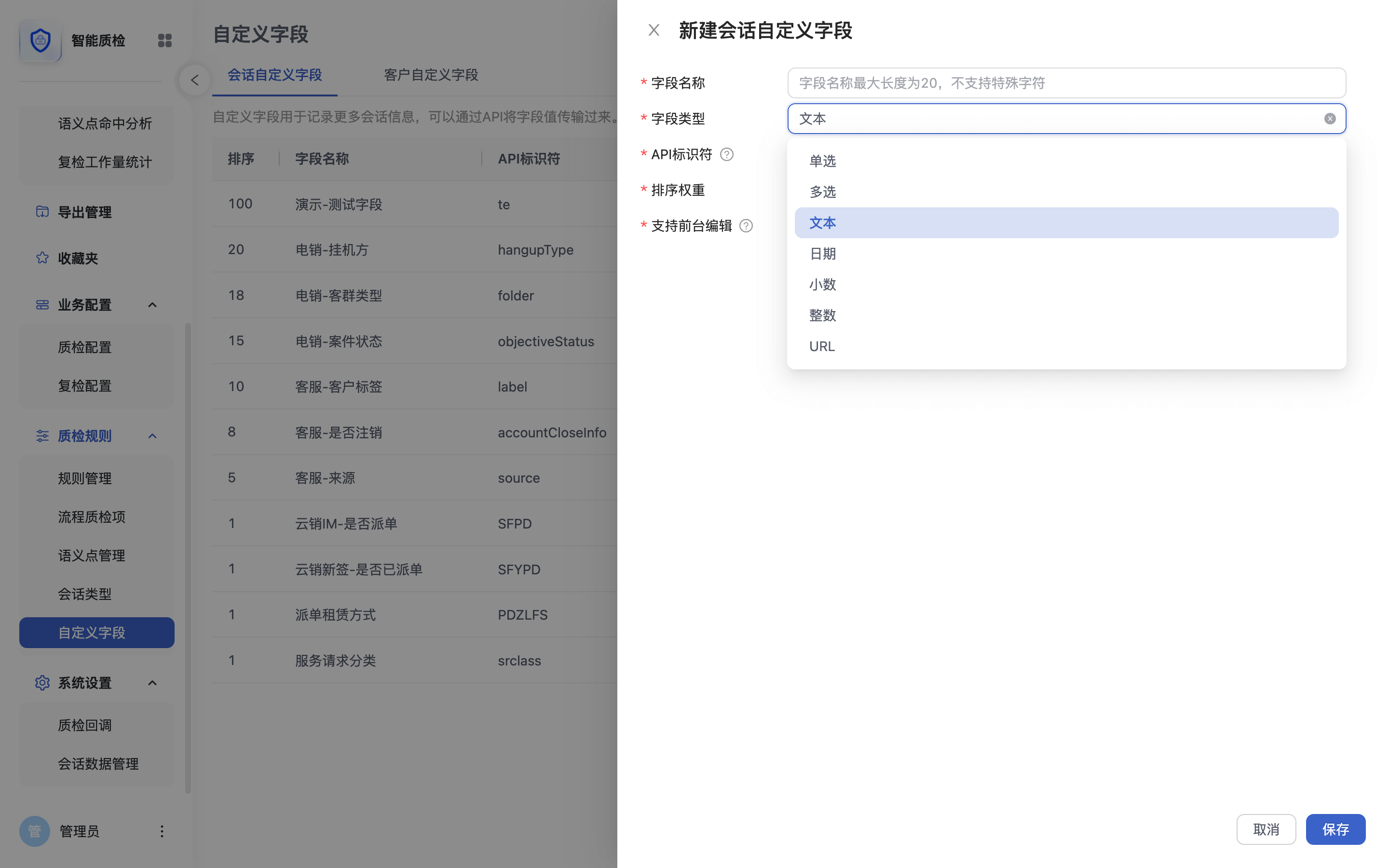
贴合业务的自定义字段
自定义字段支持单选、多选、文本、日期、小数、整数、URL等类型。
在流程质检中,可以借助自定义字段信息,实现更加精细化的质检。
自定义字段可通过API形式上传的关于会话或客户的补充信息。
质检系统对企业自定义字段的支持程度越高,质检系统与业务的贴合度,以及质检的精细化程度才能越高。
-
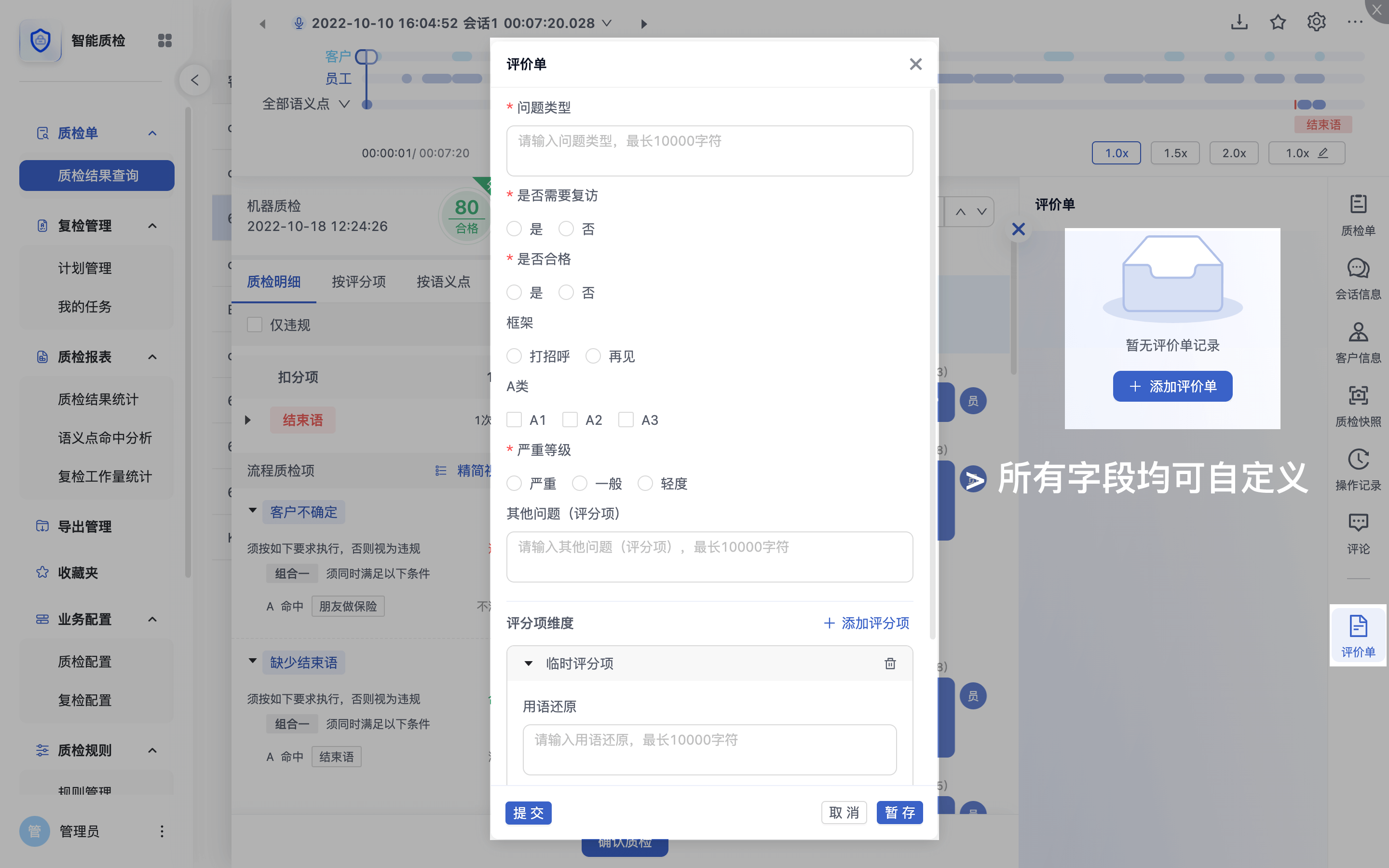
一键对接工单系统
会话质检的结果需要存档到企业自己的质检结果明细系统中,以备监管机构查询。
质检/复检人员一键就可在线选填生成完整质检报告。
通过“评价单”功能可将质检结果明细信息,通过API接口提交到台账系统中。
-
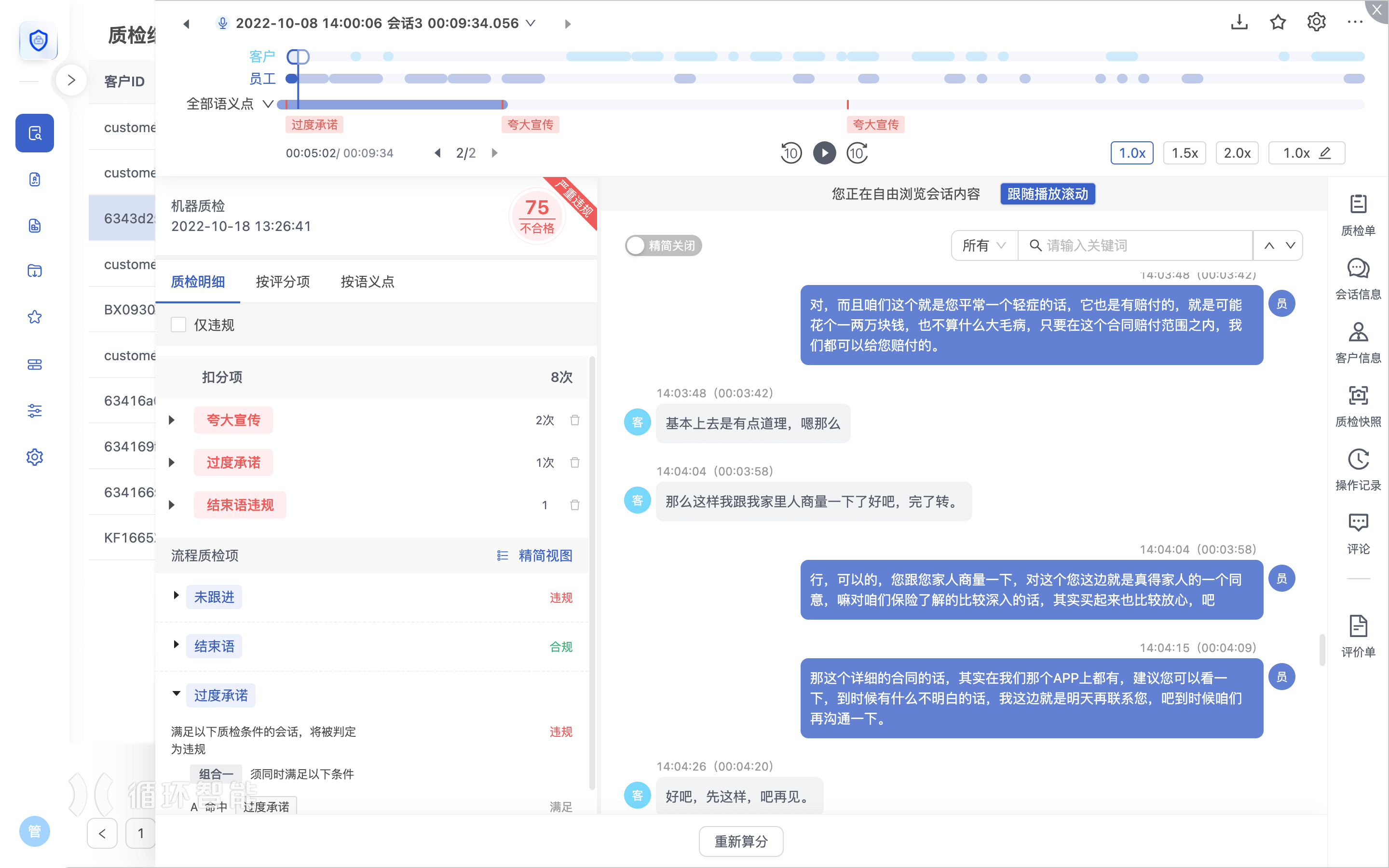
可视化的系统界面
顶部播放器的外观设计更加简洁,帮助人工复检员快速定位录音的关键位置。
左侧机器质检结果的呈现更加清晰,可以按质检明细、按评分项、按语义点快速查看机器质检的结果。
右侧的侧边栏支持快速折叠或展开,让人工复检员可以集中精力于更重要的会话内容本身。
产品和技术核心优势
-

 全自研ASR、NLP等核心技术,保障更高的违规检出率
全自研ASR、NLP等核心技术,保障更高的违规检出率- 自研ASR语音转写算法,支持灵活高效地优化企业专有名词,可快速响应业务需求变化。
- 语义理解NLP模型基于原创的先进模型 XLNet,可以识别超长上下文的语义。
- 支持盘古零样本NLP平台快速生产语义模型,提升数倍建模效率。 -
 创新的关联质检、流程质检等核心功能,更贴合业务需求
创新的关联质检、流程质检等核心功能,更贴合业务需求- 创新的关联质检,充分满足企业“多会话、多渠道沟通”场景的质检需求。
- 创新的流程质检,支持灵活配置质检规则,适配售前、售中、售后各种复杂业务质检场景。
- 高度可视化操作体验,精听、泛听、人工复检等全流程效率更高,人均产能更高。 -
 系统可扩展性强,具备丰富的集成对接能力
系统可扩展性强,具备丰富的集成对接能力- 丰富的自定义字段支持,提升质检系统与企业业务的贴合度、质检的精细化程度。
- 质检评价单支持企业自定义设置,可直接对接企业质检工单(台账)系统。
- 新增丰富的质检数据导出功能,企业可与自身已有BI系统更好的配合进行数据分析。 -
 丰富的业务实践经验,助力企业快速落地应用
丰富的业务实践经验,助力企业快速落地应用- 循环智能在银行、保险、证券、教育、消费金融等主要行业已经积累了超过10000个质检项(质检模型)和大量行业通用质检模板,让企业可以快速落地应用起来。
- 循环智能可满足企业售前、售中、售后等全场景的对话质检需求,积累了丰富的质检业务落地经验,可助力企业更快实现业务价值。
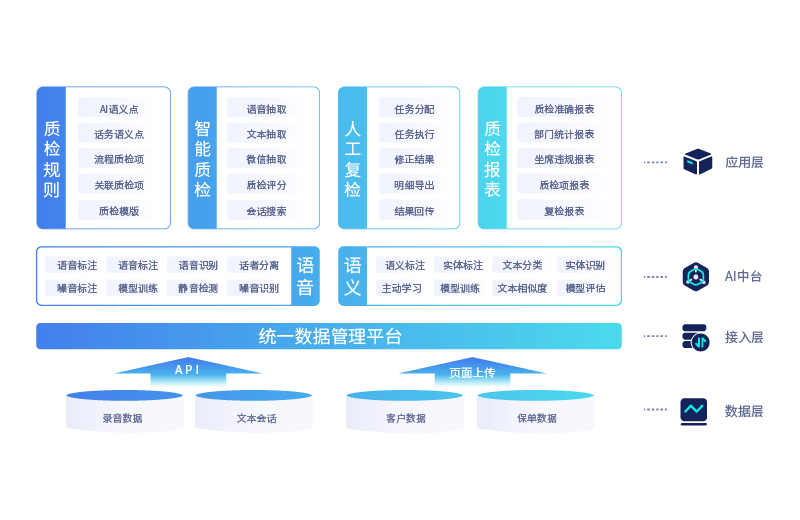
产品架构全景图
不同于基于“关键词+正则”的传统方案,循环智能提供高准确率和召回率的“非正则”方案,可助力质检员多找出2~10倍违规对话。最近,智能质检产品(Compliance)迎来新版本升级,不仅对包括关联质检、流程质检、自定义字段在内的关键能力进行了全面迭代,满足企业更加多样化的合规质检和SOP质检需求,而且升级了软件的用户使用界面(UI),提升质检效率和用户操作体验。




















为什么选择循环智能




-
 更低成本的集成对接
更低成本的集成对接

丰富的上下游系统对接经验:CRM、CallCenter、产品库等
提供IT咨询服务,支持私有化定制
即插即用的SDK模块
标准化API数据接口
丰富的最佳对接实践/案例
-
 更便捷的部署运维
更便捷的部署运维
服务期内免费升级,支持跨版本升级
微服务架构/高可用/支持动态扩容
自动化部署/容器化部署
三级等保认证,数据安全更有保障
-
 更快的价值落地
更快的价值落地
丰富的行业实践与成功经验
专属交付团队,以业务成功为导向的交付标准
全方位的销售数字化咨询服务
行业专家全程陪伴式业务增长咨询服务
提供销售素材供应服务和内容挖掘服务
众多行业客户的信赖







































































提升销售团队与客户经营的效率,就从现在
循环智能的解决方案专家可为您远程或上门演示产品

