
受访者 | 杨植麟,循环智能联合创始人
记者 | 徐威龙,编辑 | 郭芮
出品 | CSDN(ID:CSDNnews)
「AI技术生态论」人物访谈栏目是CSDN发起的百万人学AI倡议下的重要组成部分。通过对AI生态顶级大咖、创业者、行业KOL的访谈,反映其对于行业的思考、未来趋势的判断、技术的实践,以及成长的经历。本文为该系列访谈的第12期,通过和循环智能联合创始人杨植麟的访谈,本文详细解读了XLNet模型等自然语言技术以及对话数据的应用场景等内容。
近年来,由于面向大规模用户的音频、视频、图像等业务急剧增长,全球数据量呈现出爆发式的增长,“数据石油”也为无数的科技公司提供了“覆手为云”的发展契机。数据预测,到2020年全球的数据量将到达40ZB,车联网、智能制造、智慧能源、无线医疗、无线家庭娱乐、无人机等新型应用都将创造出新的数据维度。技术换代下,伴随着数据海啸而来的“淘金热”也居高不下。
事实证明,数据带来的机会是极为庞大的,但目前人们还未能彻底挖掘出数据资产的全部价值。在过去,对话数据的“含金量”就一直被严重忽视了。
随着自然语言处理技术的不断发展,时下的对话数据价值正在逐渐被唤醒,不同领域的最佳行业实践和实际效果都在逐步提升——而那些富有远见的企业,已经开始重视对话数据的价值了,但是他们之中的很多人仍缺乏利用这些数据产生业务价值的最佳实践。循环智能则正是基于此出发点,填补了这一技术空缺。
基于原创的XLNet模型、Transformer-XL模型等自然语言处理底层技术,循环智能打造了领先的AI技术矩阵。“我们做的事情主要就是:从销售过程产生的对话数据中,包括跟企业的IM聊天、微信聊天、电话销售沟通,进行文本的洞察,实现决策层面的赋能,最终提升销售的转化率。”针对不同行业的具体需求,实现不同的对话数据应用场景落地。在本文中,CSDN采访了循环智能联合创始人杨植麟,其将从对话数据的应用场景出发,为我们全面解析XLNet模型原理、核心技术、当前NLP的发展以及AI人才成长路径等内容。
在深度学习和自然语言处理领域,杨植麟颇有建树。作为第一作者,其与卡内基梅隆大学、Google Brain团队联合推出NLP领域热门的国际前沿预训练XLNet模型,在20个标准任务上超过了曾经保持最优性能记录的Google BERT模型,并在18个标准任务上取得历史最好结果,更被称为“BERT之后的重要进展”。
 △ 杨植麟与两位导师Ruslan Salakhutdinov(苹果 AI 研究负责人,右)、William Cohen(谷歌 Principal Scientist ,左)合影
△ 杨植麟与两位导师Ruslan Salakhutdinov(苹果 AI 研究负责人,右)、William Cohen(谷歌 Principal Scientist ,左)合影在北京智源人工智能研究院公布的2019年度“智源青年科学家” 名单中,他还是最年轻的、也是唯一的“90 后”。
分析对话语义,挖掘数据价值
发挥数据价值已成为大多企业的共识,在这其中,很多企业出于提升服务水平和效率、保存企业数据资产的原因,存储了大量销售与客户、客服与客户沟通的录音、文本记录。如何从对话数据中找到对企业有用的信息、挖掘出客户所表达内容中隐含的潜在产品需求——则是循环智能的技术初衷所在。
他表示,目前具体有四个场景:第一,使用对话数据,做高意向销售线索的挖掘、排序和打分,给每一个线索做解决方案匹配和产品推荐;第二,从对话数据中抽取客户画像,帮助企业构造画像体系。企业借助画像体系可以设计针对性的运营活动;第三,从对话数据中自动挖掘销售的有效话术,这些有效话术可以为销售新人做实时辅助,告诉新人更高效地与客户沟通;第四,监测话术的执行情况,这个过程通常被称为执行力监督或质检。“同时,我们通过分析对话的语义跟最终结果——是否成单之间的关系,预测哪些对话有更高的成单意向,从而让这四个场景形成闭环。”在实际案例上,杨植麟分享了一个比较Top的寿险公司应用,“我们的线索评分上线之后,大概通话时长提升了100%,转化率提升了到原来的270%。”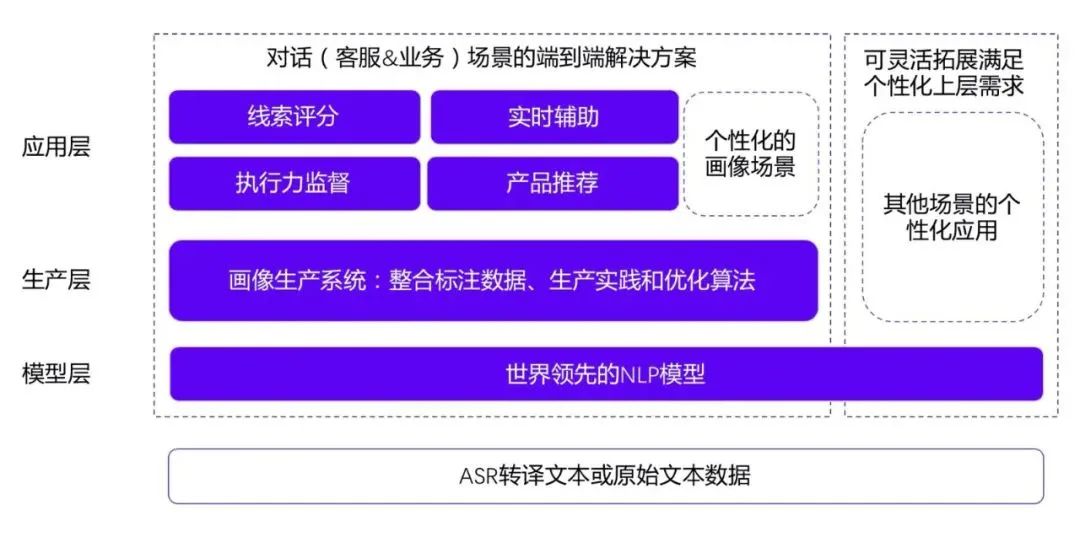 △ 循环智能的产品架构图
△ 循环智能的产品架构图技术层剖析:XLNet 优于 BERT
“在技术实现层面,我们所做的事情和实现的场景,跟传统的对话机器人、聊天机器人或者机器人客服,都有着极大的差别。”杨植麟表示,机器人主要做的事情是通过一套模板做简单的匹配,匹配之后用规则去生成接下来要说什么。从技术上说,目前机器人公司基本上没有使用新一代技术,而循环智能所做的业务场景则是帮企业做产品与客户的匹配、销售线索推荐,这些场景直接影响企业的业绩,因此企业对准确率非常敏感,必须使用最新一代的、更高准确率的技术才可以。“我们用了自己原创的XLNet算法去做很大的模型,用很多的数据去学习,使得标注的效率、对文本长序列的处理都取得了很大提升,可以来支撑我们的上层业务。”此外,还能更好地结合上下文语义,从沟通对话数据中实时提取语义标签,来做合规质检、客户画像和反馈的自动挖掘、销售和客服的执行力监督。在杨植麟看来,相比BERT,XLNet模型有其明显的优越性。原理上,两者都是属于预训练的方法。但从更具体的角度来说,XLNet其实是融合了两种不同的预训练方法:自回归和自编码两种。“BERT可以看成是一种自编码的方法,XLNet则会克服BERT的一些缺点”,主要是两个:XLNet不用引入特殊的Mask符号,所以会减轻在预训练和微调(Fine-tuning)时候数据分布不一致的情况;此外,XLNet可以对不同词之间的关联性进行建模,而BERT假设所有要预测词之间都是独立的。XLNet通过一些比较巧妙的、形式上的变化,使得它不需要有这个假设。“所以XLNet是一个更通用的模型,去掉了比较严格的假设,可以对自然语言里面的上下文关系进行更好地建模。”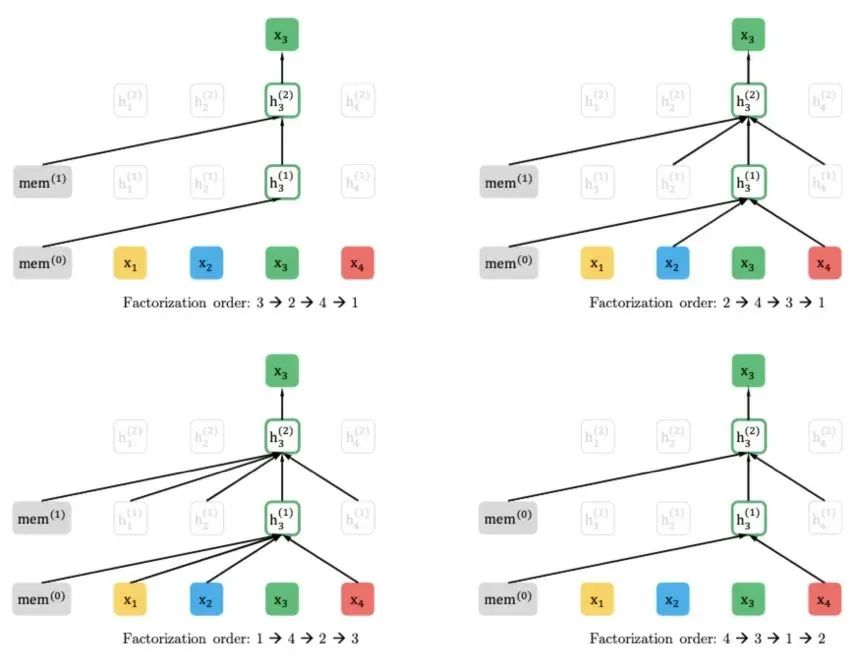 △ XLNet原理图在具体的产品和解决方案背后,循环智能同样面临着两方面的技术难点。一方面,他们需要将自己提出来的模型用到业务场景里面,另一方面是要针对具体场景里的一些挑战,针对性地提出技术解决办法。具体来说,“第一块主要是用了我们提出的Transformer-XL、XLNet等一系列通用NLP模型,以及一些主动学习(Active Learning)的算法,作为底层去支撑上层的应用。第二块就是针对这些具体的场景,它相对来说会有一些比较难的地方。”难点1:线索评分会涉及到怎么去融合多种不同模态的数据。比如除了对话数据,有时候还会有行为数据、业务数据,需要将不同模态的数据融合到同一个框架。
△ XLNet原理图在具体的产品和解决方案背后,循环智能同样面临着两方面的技术难点。一方面,他们需要将自己提出来的模型用到业务场景里面,另一方面是要针对具体场景里的一些挑战,针对性地提出技术解决办法。具体来说,“第一块主要是用了我们提出的Transformer-XL、XLNet等一系列通用NLP模型,以及一些主动学习(Active Learning)的算法,作为底层去支撑上层的应用。第二块就是针对这些具体的场景,它相对来说会有一些比较难的地方。”难点1:线索评分会涉及到怎么去融合多种不同模态的数据。比如除了对话数据,有时候还会有行为数据、业务数据,需要将不同模态的数据融合到同一个框架。
难点2:怎么对很长的对话结构的文本进行建模。用预训练好的模型通常效果不好,因为它一无法有效地对对话结构进行建模,二没办法对很长的文本序列进行建模,所以要对模型进行改进,我们现在可以处理长度几千个词的文本。
难点3:规模化生产没有办法非常依赖标注数据,所以需要提升标注的效率。通过小样本学习的思路,上了一套新的系统,现在只用10%的标注量,就可以达到跟以前一样的效果,这对规模化复制业务有非常大的帮助。“做实验的时候,你每一个新的想法不一定都能Work。” 杨植麟认为更重要的是在应对瓶颈的时候,把心态变得更好。“很多时候,你不是需要追求做实验一直不失败,而是要用更快的速度去迭代,用更快的速度取得结果。”NLP 辉煌时代已至
最近几年,语音识别、计算机视觉、语言理解等技术的“崛起”使得沉寂了半个多世纪的人工智能再次火爆起来。事实也证明,人工智能不仅仅是需求驱动,而且是内生驱动。杨植麟认为,算法和算力其实是一个螺旋螺旋式上升的过程。“人工智能的驱动方式是算力和算法螺旋型上升、相辅相成。一开始算力非常小,科学家只能去研究最好的算法。但是等到算力大的时候,很多算法就没用了。很多论文都有这种问题:在算力小的情况下跑了一下效果不错,但是算力大的时候,一点用都没有。”“本质上,在算法和算力互相迭代的过程中,最新一代的算法解决了大数据和大模型这两个问题,比如说做NLP的话,那大模型就是Transformer,大数据就是通过预训练来解决的。”也正是大模型+大数据的“繁荣”,直接造就了当下NLP的辉煌时代。他表示最近几年NLP领域有两大突破:第一个突破是从模型的角度看,从简单的模型演进到了基于Transformer的大模型。Transformer的好处是随着参数的变多,效果不断变好,而且具有非常强的长距离建模的能力。Transformer模型这两个优点,使得现在可以做到很多以前做不了的事情。第二个比较大的进步是思维范式上的转变,诞生了基于预训练的方式,可以有效地利用没有标注的数据。“简单来说,Transformer是模型角度的突破,预训练方法是思维范式上的突破,前者解决的是如何训练一个大模型的问题,后者解决的是如何解决NLP没有大数据的问题。”对于那些想要扎根AI领域的开发者来说,杨植麟表示把握当下的时代契机十分重要。“想学习AI开发技术,我觉得可以分两条路径:第一条路径是自上向下的、系统性的学习。比如看一本比较系统性的教科书,或者网上的课程,帮助你对整个领域的知识脉络有一些系统性的了解;第二条路径是自底向上、需求驱动的做法。就是说,你先遇到现实中的一个问题, 然后从这个问题出发,通过各种网上的搜索工具去调研相关的文献。”而最最重要的是,“一定要去写代码!”,或者去跑一些真正的代码,而不仅仅停留在看的层面——实践很重要。从“人机单独作战”到“人机耦合”,AI 终将赋能沟通“在人工智能领域,我最欣赏‘神经网络之父’Geofrey Hinton,因为他是最早的奠基人,重要性不言而喻。”也是他,驱使杨植麟多年来在自然语言处理领域持续深耕下去,此外,“我觉得语言本身比较有意思,语言是人类知识和认知的载体,如果机器能够理解语言,然后在理解语言的基础上进行推理,去做出一些决策,其实是一种很高级的智能的表现,这也是人工智能领域比较重要的话题。另一方面则跟时机有关,因为我四五年前开始做研究的时候,计算机视觉CV或者语音识别这两块已经取得突破了,很多效果已经做得比较好了。但NLP仍缺少一些突破,我觉得这个领域会有更多有挑战性的问题需要去解决。”而Google、Facebook等顶尖公司的工作经历,也为他后来的成功创业打下了基础。“在这两家公司有两个最直接的收获:其一就是做了一些研究成果出来,现在我们也在实际落地运用,包括Active Learning(主动学习)的思想、预训练模型,都可以直接用上;第二个收获,更偏的方法论。就是说,遇到一个问题的时候学着将大的问题拆成小的问题,然后逐个击破。我觉得其实创业跟研究有很多方法论上共通的地方。”但在AI真正去赋能沟通的坦荡前路上,还有一些亟待突破的技术难点。他表示主要有三个方面:第一,从“人机单独作战”到“人机耦合”。现在市面上做对话机器人的公司最多,它们做的事情其实是“人机单独作战”。比如在销售场景下,把销售线索先让机器人去跟进,然后其中比较好的再让人去跟;在客服场景下也是一样,先用机器人去接一些简单的问题,难的再交给人工客服去接。这其实是一个割裂的状态,机器人和人做的是独立的任务,没有实现协同。“我们希望让人和机器更好地耦合,比如在销售过程中,机器给业务员提供辅助,协助人做决策,或者机器给人推荐方案,由人去执行方案。我觉得“人机耦合”最终会成为销售场景比较好的形态,而不仅仅是人和机器分别作战。”第二,从比较浅层的客户触达到深度的决策输出。还是对话机器人的例子,他们做事情主要是用自动外呼机器人给客户传递一些简单信息,或者是问一些简单问题收集一个问卷,或者做个提醒功能。这些其实是比较浅层的触达,就是说机器人只负责传递信息,而且是较为浅显的信息。“我们做的事情是让机器学习或者NLP算法深度参与到最重要的销售决策过程,包括应该去跟进哪些人、给他推什么东西、如何与客户做沟通等。”第三,要让机器能有自学习的能力。“当我们做到人机耦合、机器可以跟人一起工作,那机器就需要能根据人的行为或者人的决策产生的结果,去自动更新和升级算法模型,形成闭环,帮助销售能力一直演进下去, 而非停留在静态模型。”

























-620.svg)






